当数据挖掘遇上战略决策
更新时间:2023-10-10 09:57:43•点击:9986092 • 行业观点

数据挖掘的定义与价值
数据挖掘指从大量数据(包括文本)中挖掘出隐含的、未知的、对决策有潜在价值的关系、模式和趋势,并利用这些知识和规则建立用于决策支持的模型,提供预测性决策支持的方法、工具和过程。通常,数据挖掘会用到应用数学、统计学、数据库技术、机器学习和人工智能等多种技术。
在企业经营管理过程中,数据挖掘可以帮助企业发现业务趋势、揭示客观规律、预测未知结果、优化战略决策的效率与效果,同时,数据挖掘还可以帮助企业优化业务运营的流程,提升用户与员工的体验。用好数据挖掘工具,构建基于数据驱动的战略决策(Data-Driven Decision-Making (DDDM))体系,将让企业在面向未来不确定性时做出明智的战略抉择。
机器学习的分类与经典模型介绍
机器学习是数据挖掘的重要技术支撑,根据学习范式的不同,机器学习可划分为有监督学习、无监督学习、强化学习和深度学习。有监督学习指从有标注训练数据中推导出预测函数,一般用于解决预测或者分类问题;无监督学习指对无标签样本进行学习揭示数据内在规律,从给定数据中找到隐藏的模式和见解,一般用于解决聚类或者关联关系探查等问题;强化学习不依赖标注数据,用于描述和解决智能体(agent)在与环境的交互过程中通过环境给予的反馈(奖励)学习策略以达成回报最大化或实现特定目标的问题。深度学习指使用神经网络模型来学习数据的特征,可以在大规模数据上进行训练。
机器学习的分类
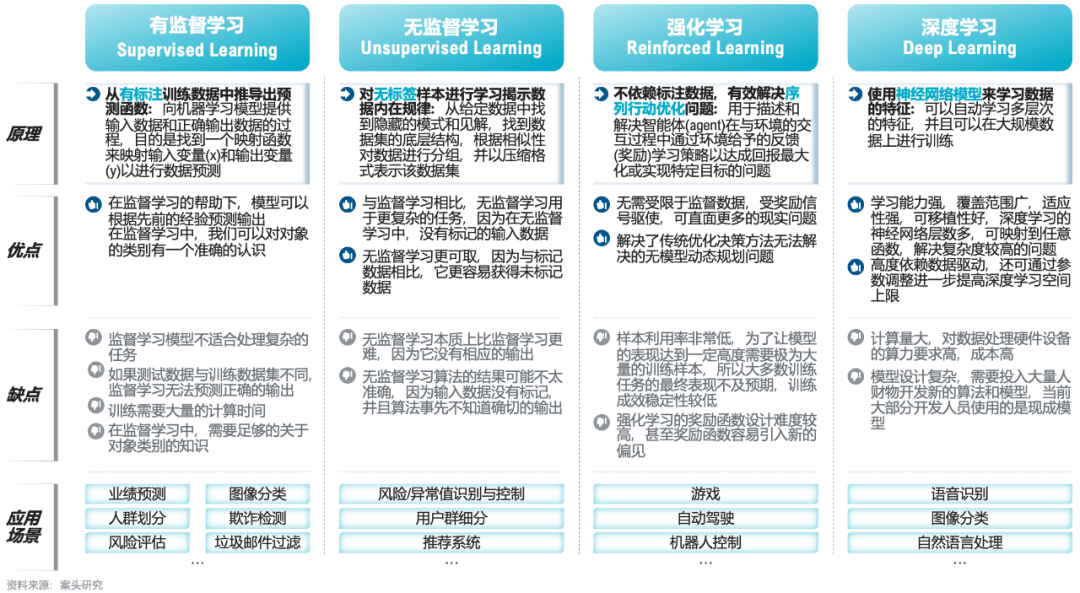
其中,有监督、无监督学习是主流常用的机器学习模型,在企业战略决策中有着丰富的使用场景。有监督学习使用的算法模型包括线性回归、逻辑回归、时序模型、决策树模型,无监督学习使用的算法模型包括K-means、PCA、DBSCAN、Apriori等。
经典模型的介绍



建模的步骤与流程
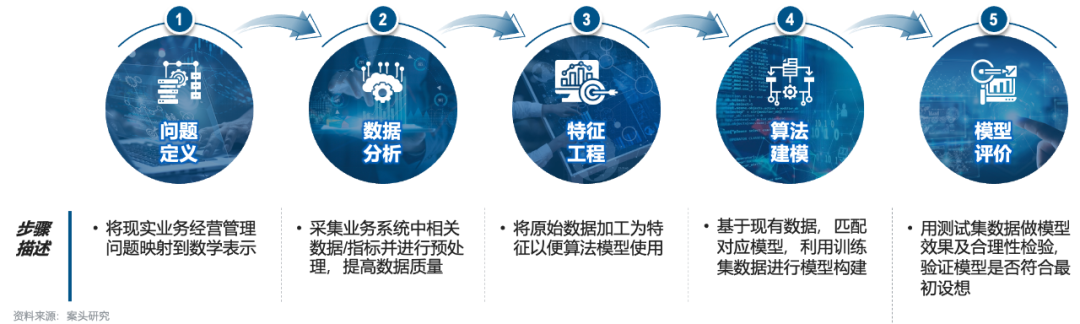
应用数据挖掘辅助战略决策分为5大步骤:问题定义、数据分析、特征工程、算法建模与模型评价。
问题定义:将现实业务经营管理问题映射到数学表示,明确数据挖掘目标。
数据分析:包括取样、探索及预处理三个步骤,核心目的是提高数据集。
特征工程:是把原始数据转变为模型的训练数据的过程,目的是获取更好的训练数据特征,使得机器学习模型逼近训练上限。
算法建模:是数据挖掘工作的核心环节,需要思考建模属于数据挖掘应用中的哪类问题并选用对应算法进行模型构建。
模型评价:需要一组没有参与预测模型建立的独立数据集,即测试集数据,评价预测模型的准确率。
建模步骤与流程
数据挖掘在战略决策中的实战案例
实战案例①:帮助某酒店集团进行常住酒店公寓选址
案例关键词:#酒店行业# #有监督学习# #回归模型# #决策树模型#
客户核心诉求:提高常住酒店公寓项目选址决策效率,在城市中筛选住客入住需求集中的地块,保证项目投运后的收益。
数据挖掘步骤:
● 定义挖掘目标:合理进行门店的规划选址,选择潜在高销量区域。
● 分析地块数据:导入已有门店信息、门店销量、竞品门店销量、宏观指标、市场表现等数据,开展数据分析。
● 构建特征工程:包括门店特征、地块特征、城市特征、竞品特征等。
● 决策树建模:采用决策树模型在训练集进行训练,对备选区域在地块得分、竞品门店数量、投资回报周期等关键选址决策要素下的表现进行分类。
● 效果验证:在测试集对算法模型进行效果验证,并进行合理性分析。
● 选址决策应用:在不同区域应用选址决策模型,输出门店选址与扩张策略。
建模步骤与流程
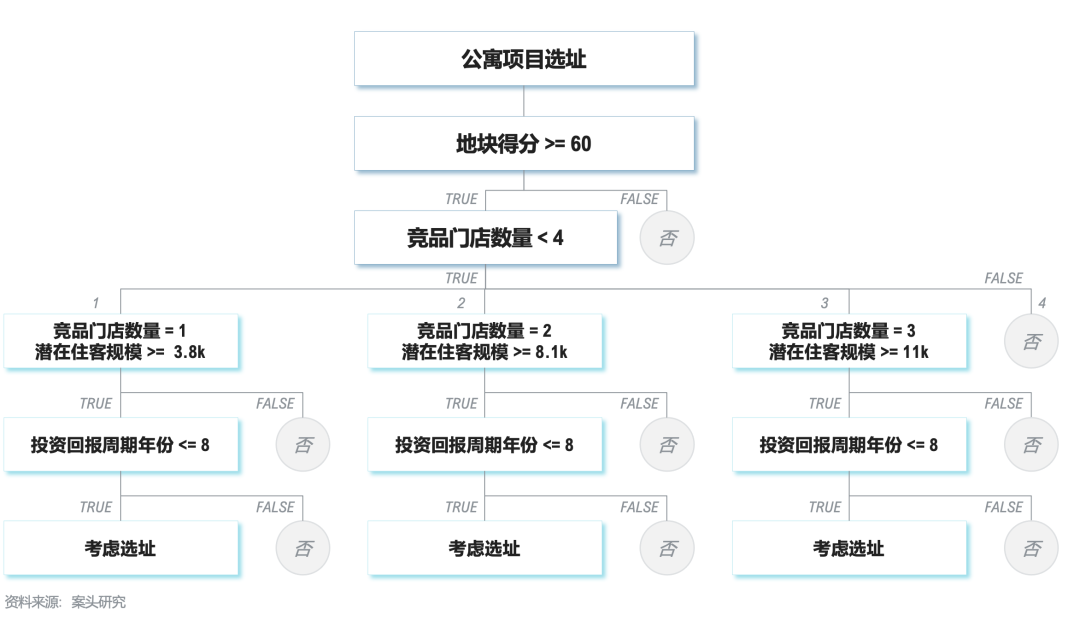
战略决策输出:在试点城市跑通模型后输出标准化选址决策机制,可在集团内部其余区域业务扩张过程中提供决策支持,同时根据不同城市地块的模型决策结果追踪辅助判断地区业务发展空间及潜力,适当调整区域业务战略侧重,聚焦重点区域及重点地块的资源投入。
实战案例②:帮助某鞋业公司搭建畅销商品补货模型
案例关键词:#鞋服零售# #有监督学习# #时序模型# #补货预测模型#
客户核心诉求:对门店内的畅销款式销售数据进行挖掘,构建销量预测及补货预测模型,以尽可能小的库存,为畅销款高效配置库存、销售资源,最大化畅销款的销售机会。
数据挖掘步骤:
● 挖掘目标定义:通过及时、足量补货等手段,以尽可能小的库存,为畅销款商品高效配置资源,实现销量最大化。
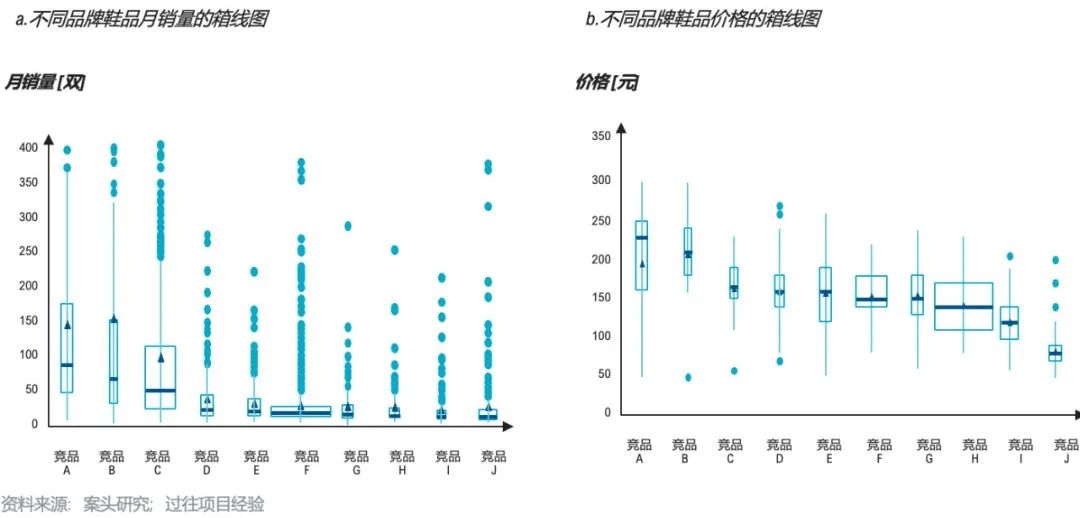
● 数据取样与探索:挖掘门店、仓库数据体系中的销售、进货、库存指标,探索指标相关性。
● 数据预处理:基于数据计算为各类商品贴标签,包括“毛利率水平偏高”、“库存水平偏低”、“新货品”等标签。
● 特征开发:剔除部分标签,如“库存水平偏高”、“连续三周销售下降”,保留与畅销货品高度相关的标签作为模型特征。
● 模型构建:根据时序模型构建“滚动销量预测算法”,输入季节、货品销量、性别、风格细类等相关特征。
● 模型测试:利用测试集数据开展模型测试。
基于数据分析为各类商品贴标签
根据时序模型构建“滚动销量预测算法”
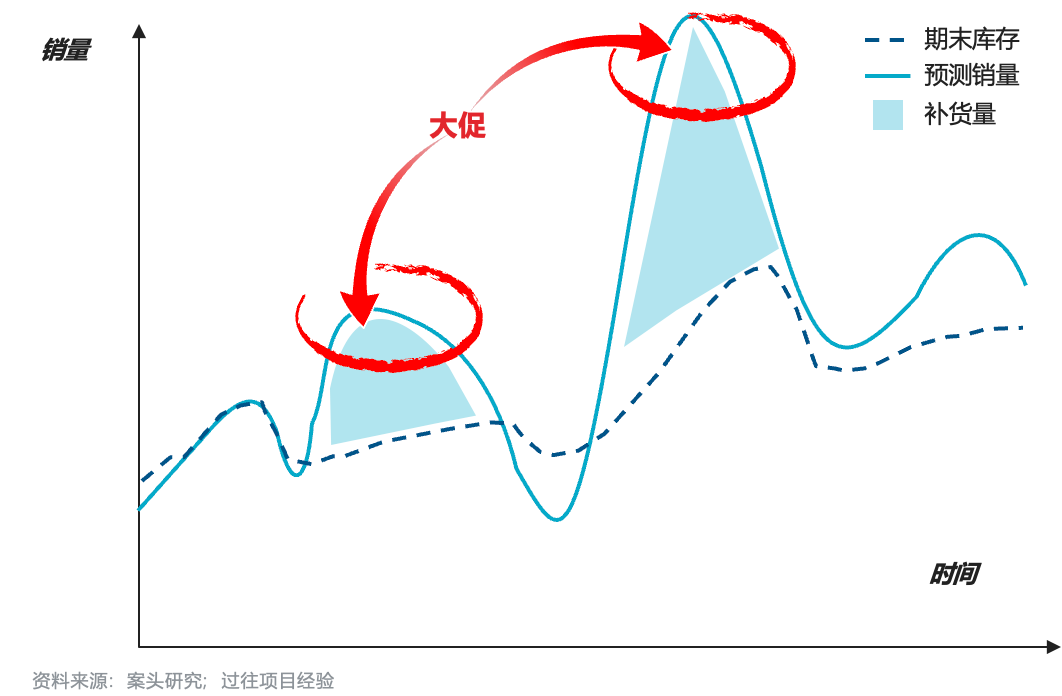
战略决策输出:根据预测销量,测算期末库存以制定大促期间的到货计划,若(上周期末库存-当周预测销量)<0,则需以订货数量的倍数进货,并基于到货计划,根据供应链前置时间(lead time)进行下单,以此减少期末库存压力,高效调动库存配置和销售资源,实现爆款商品销量最大化。
实战案例③:帮助某零售连锁企业进行门店分群与经营评估
案例关键词:#零售行业# #无监督学习# #聚类分析# #门店经营评估#
客户核心诉求:对已有门店进行分群,挖掘不同类别门店特征,识别优秀或异常门店,焕新门店分类管理策略。
数据挖掘步骤:
● 挖掘目标定义:通过提取门店的各类特征,构建门店经营评估与分群模型
● 数据取样与探索:选取数据库中的商户属性、经营信息、风险信息等相关数据指标。检验租金、销售数据是否符合正态分布规律。
● 特征开发:对数据进行取值SQL、取值维度、指标缺失值、指标异常值、指标一致性等特征处理。
● 模型构建:通过降维,筛选出从数据视角分析得出的关键因子,确定最终的因子并构建算法模型。
● 门店分群:每个群组门店特征会呈现差异,针对不同群组的特征进行分析,识别不同类型门店特征,确定门店划分标准与分群结果。
● 成因分析:基于门店特征挖掘结果,选取有代表性门店开展生命周期分析。
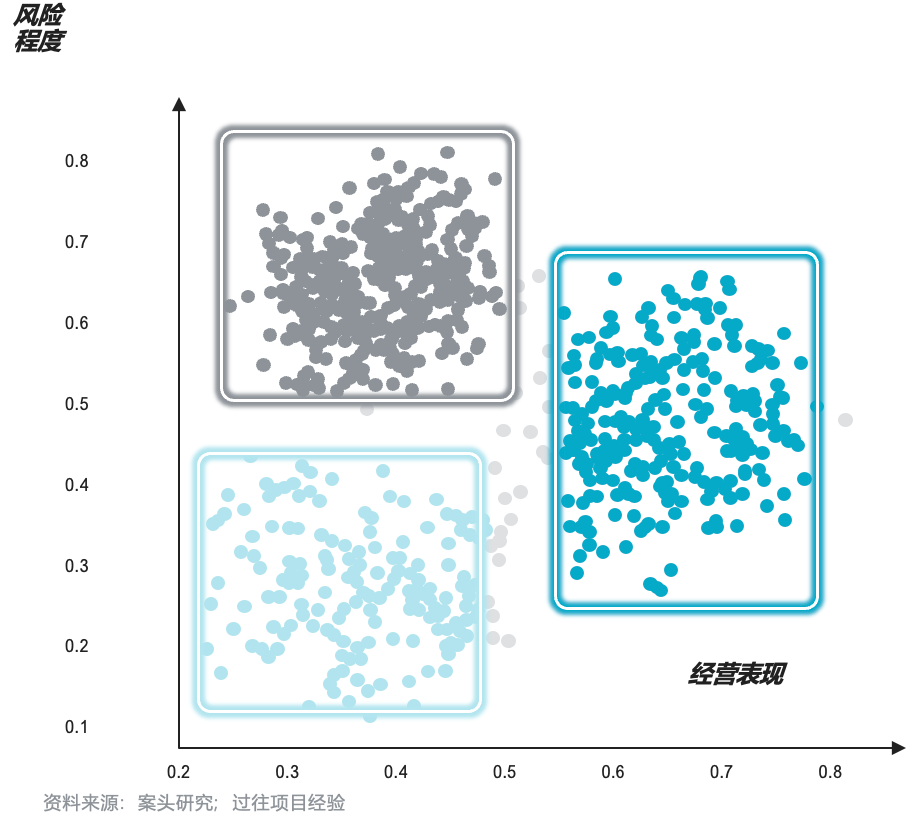
战略决策输出:根据模型聚类的三类门店特质,匹配差异化管理举措。对于表现优秀的门店,挖掘其成功经验并在其他门店进行推广,对于存在潜在风险的门店可及时进行干预。
聚类分析模型:在未设定标签的情况下,根据数据相似度进行分组
结语
经验主义哲学家弗朗西斯·培根曾说过:“我们大部分的人的理解力容易出现偏差,我们的心智容易被假象所困住。”在现代企业的战略决策中,管理者的战略判断也常常会受到固有认知、个人直觉或理解偏差所影响。数据挖掘的意义在于帮助管理者从大量的数据中去提取那些隐藏其中的、预先未知的、但有潜在价值的客观规律,让管理者在进行决策时有更坚实的依据与更充分的论断。
数据从来不是全部,数据也不能替代思考,但他可以让你站在巨人的肩膀上。
推荐阅读
-
当数据挖掘遇上战略决策
2023-10-10 09:57:43•9986092 次
-

WIPO:2023年全球创新指数报告
2023-10-10 09:52:25•9062479 次
-

阿秒激光技术是否将成为物理学的未来?
2023-10-10 09:23:50•9272226 次
-
与IT决策者们共同探寻中国数字化转型之路
2023-07-29 21:25:26•6419036 次


